Deep Learning 101
02 May 2015 . research . Comments #DeepLearning
Deep Learning has come to become a far more important chunk of technology than simply a buzzword. With the onset of the third internet wave and the outburst of Big Data, Machine Learning and their derivatives researchers had begun to ask questions about how the human imagination might work? Can we induce this intelligence that humans own into a machine? How do we transfer intelligence?
Much like the build up towards the first industrial revolution that was spearheaded by the invention of the steam engine; machine learning today, has opened up profound treasure of scientific problems which have the potential to answer questions like how we human beings learn, unlearn and relearn. It would also shed light on how we perceive our surroundings and convert it into sensible signals that the brain processes. This post is targeted at laymen and newcomers from different domains. We’ll try to understand the basic claims and concepts of deep learning.
The first acceptable results for successful deep learning was demonstrated about six years ago when Prof. Geoff Hinton, a cognitive psychologist and computer scientist who works part-time between University of Toronto and Google published some results on handwriting recognition.
Conveniently, this five layered deep learning approach had beaten the state-of-the-art recognition system for the MNIST handwritten digits dataset. Prof. Hinton’s hypothesis was that the digits could be recognised by not only traditionally combination the features but a reverse mapping of the associative memory from the layers could also lead to ultimately recognising the particular digit. That is, given the conceptual setting for a digit, the machine would recognise the intended character.
What do we mean by conceptual setting? Imagine that you are reading a handwritten note and consider the fact that you probably have read similar notes before; you are capable of distinguishing between ‘5’ and ‘6’. From your previous encounters of reading someone’s handwriting, you automatically (almost involuntarily) begin to join features of a particular digit to recognise it. Prof. Bengio described deep learning as a similar process for a machine in his paper on representation learning [1, 2]. Deep learning claimed to discover many levels of features that describe a the dataset.
Looking beyond this example and the scientific clues presented herein, are we inching towards finding out how the human imagination works? This is what deep learning is set to answer.
###Where are we now? At present, machine learning algorithms require decent feature engineering and their performance is directly related. This assumes prior knowledge and domain expertise to carry out good feature selection. But how do we know if we are choosing the right features for a particular task. Representational learning is about having a generic algorithm that doesn’t depend on or require feature engineering. The goal is to capture good representational features to develop artificial intelligence.
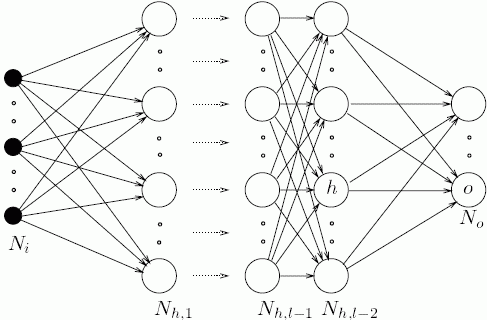
Departing from old methods of feature engineering, deep learning seek to capture good representations by using an array of non-linear transforms. It turns out that deep learning based approaches are successful in capturing the latent structural representations of input data irrespective of the domain it is applied to.
I’ll discuss the different ways to analysing deep learning architectures viz., probabilistic graph models and encoding NN models in my next post. This will be a series of posts until the point where I describe why I’m not very excited about the empirical results of deep learning and the requirement for large amounts of representations.
####References: