Understanding SVM
24 Jan 2015 . tech . Comments #SVM, Machine Learning, Research
###Introduction The task of classification is now applicable to many domains of research. From classifying malignant tumours to words in knowledge bases, classification among classes is almost everywhere.
###Why Support Vector Machines? The goal is to separate the binary classes by a function which is induced from given data such that it produce a classifier that will work well on unseen data point, i.e. it generalises well. The SV machines algorithm is proved to be a practical technique in statistical learning theory owing to its rich resource of literature.
###The dividing surface (a.k.a Margin) We can perceive this problem in two-stages, viz.,: learning and labelling. The ‘learning’ phase deals with the technique of capturing the pattern in the dataset (which shall be referred as the training set henceforth) and the labelling phase is about assigning the correct class label to the new and unseen dataset (which shall be referred as the testing set henceforth).
Now consider a dataset of data point with attributes. Mathematically . A linear model can be defined as . Since we consider a binary class problem here, takes corresponding to the two classes. is a mapping function at relates the feature space and the coordinates of the datapoint. is the feature matrix of the datapoint. is a distinct vector from the origin. To classify new datapoint into either of the classes, we are required to learn a model.
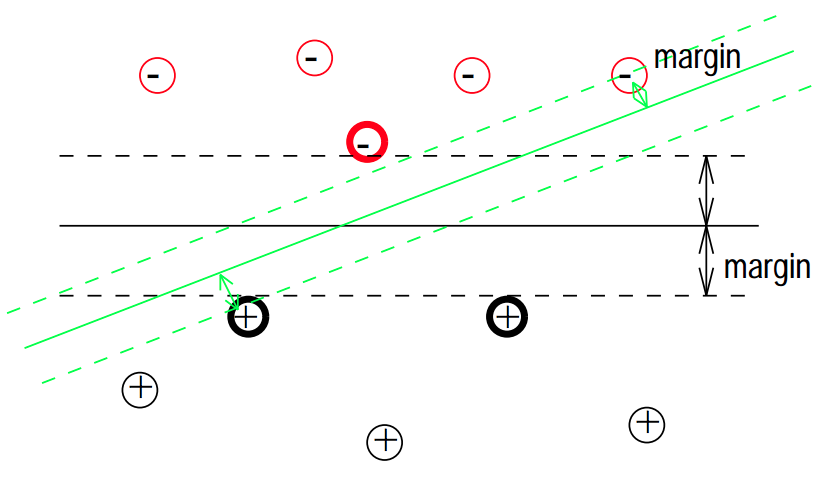
Suppose there exists a hyperplane separating the distributions of the two classes respectively. Geometrically, there can be many possible hyperplanes obtained by changing (perturbation) the values of and .We now have to arrive at the notion of the best method to identify a line, such that, the distance between the hyperplane and each datapoint is minimum.
Let’s paint out an example to understand our current position. From looking at the above image, it is clear that there are two types of points. Now, assume that we have model trained and you’re told to choose a specific datapoint within this space. To correctly classify this chosen datapoint, we refer to the fact of which side the datapoint belongs to and then declare a label. Hence, it now safe to say, if we pick the wrong hyperplane from the set of all planes obtained by varying the parameters of the linear model, our prediction will be incorrect. Intuitively the best hyperplane would the mean of all the planes which lies in the centre of both classes. In a general sense, our goal here is to minimise the error of choosing the incorrect hyperplane.
So, anything above the decision boundary should have label : s.t. shall have . Similarly, datapoints below the decision boundary should have label: s.t. shall have .
This decision boundary can be further condensed as . Hence we can verify if an instance is rightly classified by ensuring .
There is a space between hyperplane and the first elements of each class. We’ll now attempt to classify the elements from these margin such that belongs to the class with label 1 and belongs to the class with label -1.
###Maximising the margin It is clear that the margins are parallel to the hyperplane. This implies the parameters and apply to the two margins as well. Consider a point on the . Then a point on to is given by . The closest point will always lie on the perpendicular to these parallel lines. Vector is perpendicular to both lines. So the line segment will be the shortest path connecting points and and the distance between the two points will be .
Solving for :
where
{substituting }
But, w.k.t. . We’ll now substituting this in the above equation
Now putting the value of back in , we have:
Clearly, we will try to maximise this distance so that the misclassification error is reduced and thus the datapoints from each class are at the maximum distance. This is the ‘actual margin.’ Thus we must minimise a monotonic function .
###Soft and hard margins
Suppose in our previous discussions the datapoint were not uniformly distributed, a few were astray, the method of classification would fail to perform due to these outliers. In order to account for this practical behaviour of datapoints we introduce slack variables, . The reason for introducing a slack variable is to control the degree of flexibility by means of penalties.
We can conveniently formalise this into a quadratic programming problem as below:
And with the penalties:
###Problem of linear separability
Many times, mapping to a higher dimensional spaces (upto infinity, if required) make them linearly separable whereas they may not linearly separable in their original vector spaces. Consider the mapping , then the above QP can be re-written as:
.
###Lagrangian and Dual Reformulation
The technique of Lagrange multipliers captures the idea that in a particular surface in which we need to search for an optimal value, the gradient directions of both the objective and constraint surface must be oriented oppositely. Further to this,
.
This ensures that when the expression above is maximal when as is always negative. Otherwise, , so is a positive value, and this expression is maximal when . This has the effect of penalising any misclassified datapoints, while assigning 0 penalty to properly classified instances.
This can be captured in:
We now impose a constraint on the Lagrange multipliers such that and lie within . This is done to accommodate the slack variables.
A dual problem can be defined as below from the above conditions (that ):
where
Clearly, we recognise this as an optimisation problem. By setting and we find the optimal setting of as and yields a constraint respectively.
Performing a series of mathematical reductions and substitutions, we arrive at:
Thus the dual form can be written as:
###Kernel trick (having very large data points) Assume in order to obtain correct classification results, we had to map the dataset to infinite number of feature vectors, calculating may be intractable. In such situations, the dual enables this as we need to only specify the kernel matrix containing entries that represent the feature space mapping of 2 features vectors representing 2 datapoints from the dataset. It turns out that the matrix that operate on the lower dimension vectors and to produce a value equivalent to the dot product of the higher-dimensional vectors. Looking at the original space containing the untransformed dataset, we have constructed a complex non-linear decision boundary. But in order to achieve this, we have to calculate the kernel matrix, . This will lead to a computational overhead provided we use a kernel matrix.
Now, introducing the kernel trick i the dual form, we have:
###Support Vectors
Once we have learned the optimal parameters our task is rather simple. We calculate
where is our instance of a datapoint. is non-zero only for instances that lie on or near the decision boundary. These instances are called Support Vector.
###Conclusion If you have scrolled right down here. You have done just right. Look further down and the references may help you understand much better than my attempt. The objective of this post was basically two things. 1. I wanted to write down what I understood about SVMs and 2. I needed an excuse to invest time in learning to typeset using MathJax.
###References: [1] V. Vapnik. The Nature of Statistical Learning Theory. Springer-Verlag, New York, 1995.
[2] CJC Burges. A Tutorial on Support Vector Machines for Pattern Recognition. (PDF)
[3] Nello Cristianini. Support Vector and Kernel Machines. (PDF) ICML Tutorial.
[4] Jason Weston. Support Vector Machine Tutorial. (PDF)